Jean-Philippe Fauconnier
I am ML Engineer at Roblox.
Previously, I was working on Multimodal LLM at Apple I have obtained my PhD in Computer Science at the Université Paul Sabatier (Toulouse, France) and I have completed my Master Degree in Natural Language Processing at the Catholic University of Louvain (Belgium).
About
I have obtained my PhD in Computer Science at the Toulouse Institute of Computer Science Research, Université Paul Sabatier (France). My work took place under the supervision of Drs Mouna Kamel and Nathalie Aussenac-Gilles, and focused on Natural Language Processing, Document Analysis and Machine Learning fields. More particularly, I was interested in the acquisition of lexical relations using the layout and the formatting of documents. For this work, I received the ATALA Best PhD Thesis Award.
Previously, I graduated in Natural Language Processing at the Catholic University of Louvain (Belgium) in 2012. This Master's degree programme was delivered by the CENTAL laboratory.
Recent
- CubePart: Zhu, Y., Deng, K., Fauconnier, J., Navarro, I., Li, D., Pun, A., Zhang, Y., Zhuang, P., Sun, X., Agrawala, M., Bhat, K. and Zhou, T., CubePart: An Open-Vocabulary Part-Controllable 3D Generator, SIGGRAPH 2026
- Cube: Roblox Foundation AI team, Cube: A Roblox View of 3D Intelligence, Arxiv 2025
- MM1: McKinzie, B., Gan, Z., Fauconnier, J., Dodge, S., Zhang, B., Dufter, P., Shah, D., Du, X., Peng, F., Weers, F. and Belyi, A., et. al., MM1: Methods, Analysis & insights from Multimodal LLM Pre-training., Milano, ECCV 2024
- RLHF: Amirloo, E., Fauconnier, J., Roesmann, C., Kerl, C., Boney, R., Qian, Y., Wang, Z., Dehghan, A., Yang, Y., Gan, Z. and Grasch, P. Understanding Alignment in Multimodal LLMs: A Comprehensive Study., ICCV 2025 Workshop on Trustworthy FMs
- Instruction-Following: Qian, Y., Ye, H., Fauconnier, J., Grasch, P., Yang, Y. and Gan, Z. MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs., ICLR 2025
Research Interests
Natural Language Processing
- Analysis: morpho-lexical analysis and syntactic parsing
- Corpora: development of annotation tools, annotation campaigns, and inter-rater agreement evaluation
- Meaning: ontology learning from text and Word embeddings
Document Analysis
- Logical modeling: links between physical layout structures and logical ones
- LR Parsing: statistical and context-free grammar parsing for building logical tree
Statistics
- Predictive modeling: supervised classification, structured prediction and unsupervised feature selection
- Descriptive analytics: statistical relationships and multivariate analysis
Works
National journal papers
- M. Kamel, B. Rothenburger, J.-P. Fauconnier. Identification de relations sémantiques portées par les structures énumératives paradigmatiques : une approche symbolique et une approche par apprentissage supervisé. Revue d'Intelligence Artificielle, Hermès Science, Numéro spécial Ingénierie des Connaissances. Nouvelles évolutions., Vol. 28, N. 2-3, p. 271-296, 2014.
International conference papers
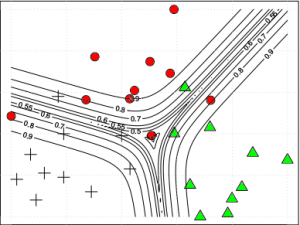
- J.-P. Fauconnier, M. Kamel. Discovering Hypernymy Relations using Text Layout (regular paper). The Fourth Joint Conference on Lexical and Computational Semantics (*SEM 2015), Denver, Colorado, 2015. PDF
- J.-P. Fauconnier, M. Kamel, B. Rothenburger. A Supervised Machine Learning Approach for Taxonomic Relation Recognition through Non-linear Enumerative Structures (short paper). ACM Symposium on Applied Computing (SAC 2015), Salamanque, 2015. PDF
- J.-P. Fauconnier, M. Kamel, B. Rothenburger. Une typologie multi-dimensionnelle des structures énumératives pour l'identification des relations termino-ontologiques (regular paper). Conférence Internationale sur la Terminologie et l'Intelligence Artificielle (TIA 2013), Paris, Université Paris 13, p. 137-144, 2013. PDF
National conference papers
- J.-P. Fauconnier, L. Sorin, M. Kamel, Mustapha Mojahid, N. Aussenac-Gilles. Détection automatique de la structure organisationnelle de documents à partir de marqueurs visuels et lexicaux (regular paper). Traitement Automatique des Langues Naturelles (TALN 2014), Marseille, Association pour le Traitement Automatique des Langues (ATALA), p. 340-351, 2014. PDF
- J.-P. Fauconnier, M. Kamel, B. Rothenburger, N. Aussenac-Gilles. Apprentissage supervisé pour l'identification de relations sémantiques au sein de structures énumératives parallèles (regular paper). Traitement Automatique des Langues Naturelles (TALN 2013), Les Sables d'Olonne, Association pour le Traitement Automatique des Langues (ATALA), p. 132-145, 2013. PDF
Phd Thesis
- J.-P. Fauconnier, Acquisition de liens sémantiques à partir d'éléments de mise en forme des textes : exploitation des structures énumératives (PhD Thesis). Université de Toulouse, 2016. PDF HAL (Best PhD Thesis Award - ATALA 2017)
Talks
- J.-P. Fauconnier. La mise en forme des textes : un indice supplémentaire pour l'identification des relations hiérarchiques (talk). Séminaire de l'équipe TALEP, Laboratoire d'Informatique Fondamentale de Marseille, 20-05-16.
- J.-P. Fauconnier. Mise en forme et indices linguistiques de surface pour l'extraction de connaissances (talk). Journées d'étude internationales S'caladis, Université Toulouse Jean Jaurès, Toulouse, 19-11-15. Abstract
- J.-P. Fauconnier, M. Kamel, N. Aussenac-Gilles. Acquisition de relations sémantiques à partir d’éléments de mise en forme des textes (talk). Séminaires du CENTAL, Université Catholique de Louvain, Louvain-la-Neuve, 21-11-14. PDF
- J.-P. Fauconnier. Métriques pour l’évaluation de l’annotation (talk). Séminaires de l’équipe MELODI, Université Paul Sabatier, Toulouse, 25-11-13. Link
- J.-P. Fauconnier, M. Kamel, N. Aussenac-Gilles. A Supervised Learning for the Identification of Semantic Relations in Parallel Enumerative Structures (poster). The 10th Summer School on Ontology Engineering and the Semantic Web (SSSW 2013), Cercédilla, 10-07-13. PDF
- J.-P. Fauconnier. Classifieur d’Entropie Maximale (MaxEnt) (talk). Séminaires de l’équipe MELODI, Université Paul Sabatier, Toulouse, 15-02-13. Link
- A. Urieli, J.-P. Fauconnier. PosTagger et Parseur Talismane (talk). Séminaires de l’Axe TAL, CLLE-ERSS, Toulouse, 20-06-12. PDF
- J.-P. Fauconnier, J. Roumier, F. Estiévenart. Musonto - A Semantic Search Engine dedicated to Music and Musicians (talk). Music Linked Data Workshop, JISC, Londres, 12-05-11. Link
Teaching
2015-2016
- Algorithms and C++ Programming - 54 hours - Université Jean Jaurès (Toulouse, France)
- Relational Database - 44 hours - Université Jean Jaurès (Toulouse, France)
- Web Integration - 40 hours - Université Jean Jaurès (Toulouse, France)
- C2I Certification - 36 hours - Université Jean Jaurès (Toulouse, France)
- XML technologies - 12 hours - Université Jean Jaurès (Toulouse, France)
- Semantic Web - 4 hours - Université Jean Jaurès (Toulouse, France)
2014-2015
- Web Integration - 24 hours - Institut Universitaire de Technologie (Tarbes, France)
- Relational Database - 18 hours - Institut Universitaire de Technologie (Tarbes, France)
- Web Integration - 18 hours - Institut Universitaire de Technologie (Tarbes, France)
2013-2014
- Web Integration - 36 hours - Institut Universitaire de Technologie (Tarbes, France)
- Relational Database - 12 hours - Institut Universitaire de Technologie (Tarbes, France)
- Information System - 12 hours - Institut Universitaire de Technologie (Tarbes, France)
2012-2013
- Office Automation - 40 hours - Institut Universitaire de Technologie (Tarbes, France)
- Office Automation - 24 hours - Institut Universitaire de Technologie (Tarbes, France)
Software
Most of resources are located on my github repository. The fast way to download a given resource is to use git:
mkdir resource
cd resource
git clone https://github.com/fauconnier/resourcePersonal softwares
AMI (Another Maxent Implementation) is a R implementation of multinomial logistic regression, also known as Maximum Entropy classifier. This implementation deals with binary and real-valued features and uses standard R functions to optimize the objective. Then, it is possible to use several iterative methods: LM-BFGS, Conjugate Gradient, Gradient Descent and Generalized Iterative Scaling.
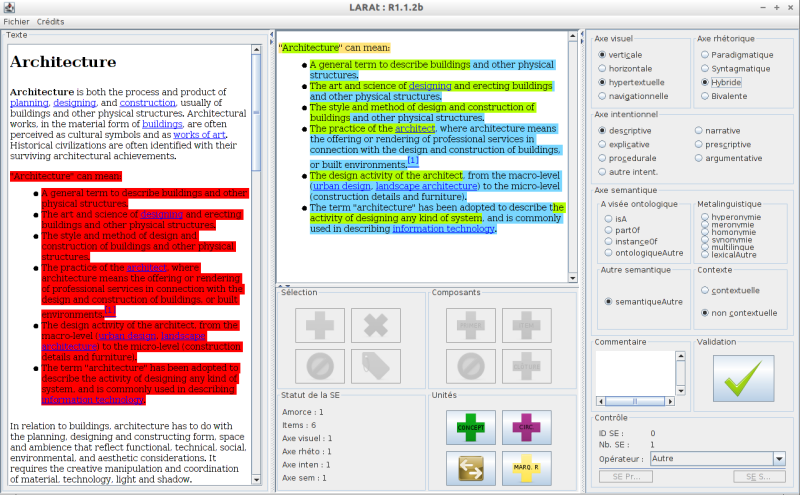
LARAt (Layout Annotation for Relation Acquisition tool), pronounced /laʁa/, is an annotation tool which supports the layout and the formatting of HTML documents. LARAt was used during an annotation campaign in 2013 and, in his current state, is dedicated to the annotation of enumerative structures. The typology implemented is the one described in the TIA 2013 paper.
LaToe (Layout Annotation for Textual Object Extraction) is a tool which extracts the text layout from HTML, MediaWiki, or PDF documents for identifying specific textual objects (such as enumerative structures). Currently, the CRF model used for the PDF analyzer was trained on a small corpus (LING_GEOP). This implies that LaToe could be not efficient for unseen PDF documents with specific formatting.
Source code reviews
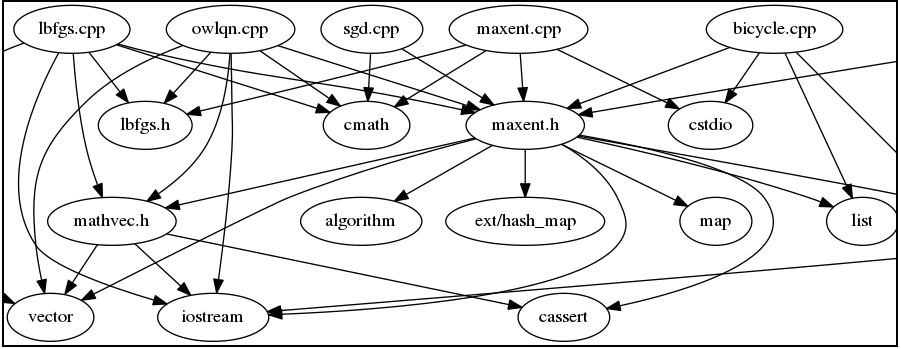
Code review of a C++ library for maximum entropy classification. On his website, Tsuruoka proposed a fast implementation of a multinomial logistic regression. In order to get a better and deeper understanding of implementation details, I propose a simple code review. The code base is relatively small (around 2500 lines of code). Those notes are primary intended for my personal use and reflect my current understanding. I propose them here, in case it could help someone. Note that this document is currently a work in progress.
Open source contributions
Some open source contributions:- 2016
- 2015
- 2014
- FREJ (Fuzzy Regular Expressions) Client-server architecture for spreading the load across a cluster. github
- YaTeA (terminology extractor) Adaptation to Talismane POS-tagset and Java client. github
- ACABIT (terminology extractor) Adaptation to Talismane POS-tagset and Java client. github
- Talismane (statistical dependency parser for French) Java client for treating corpora "on-the-fly". github
- 2013-12
- Talismane (statistical dependency parser for French) Minor fix. commit
- Talismane (statistical dependency parser for French) First version of user's manual. last version
Data
French word embeddings models
I propose here some pre-trained word2vec models for French. Their format is the original binary format proposed by word2vec v0.1c. Depending on your needs, you may want to convert those models. A simple way to convert them into text can be:
git clone https://github.com/marekrei/convertvec
cd convertvec/
make
./convertvec bin2txt frWiki_no_phrase_no_postag_700_cbow_cut100.bin output.txt
Alternatively, you can load a binary model directly into a few Python libraries. Below I give a minimal usage example with Gensim:
pip install gensim
python
>>> from gensim.models import KeyedVectors
>>> model = KeyedVectors.load_word2vec_format("frWac_postag_no_phrase_700_skip_cut50.bin", binary=True, unicode_errors="ignore")
>>> model.most_similar("intéressant_a")
[('très_adv' , 0.5967904925346375),
('intéresser_v' , 0.5439727902412415),
('peu_adv' , 0.5426771640777588),
('assez_adv' , 0.5398581027984619),
('certainement_adv' , 0.5246292352676392),
('plutôt_adv' , 0.5234975814819336),
('instructif_a' , 0.5230029225349426),
('trouver_v' , 0.5131329894065857),
('aussi_adv' , 0.505642294883728),
('beaucoup_adv' , 0.5034803152084351)]
For this model, we can see that the adjective 'intéressant' has a lot of shared contexts with adverbs. Note that the color code and the layout are mine. Please check (Mikolov et al., 2013) to gain insight into the model hyper-parameters.
Thanks to Tim V. C., Adam B., Claude C., Sascha R., Philipp D., Nirina R., Ian W. and Antoine V. who all helped in retrieving some of the original models.
frWac2Vec
FrWac corpus, 1.6 billion words.
| lem | pos | phrase | train | dim | cutoff | md5 | |
| bin (2.7Gb) | - | - | - | cbow | 200 | 0 | 7e49 |
| bin (120Mb) | - | - | - | cbow | 200 | 100 | 5b5f |
| bin (120Mb) | - | - | - | skip | 200 | 100 | 6b86 |
| bin (298Mb) | - | - | - | skip | 500 | 100 | af38 |
| bin (202Mb) | - | - | - | skip | 500 | 200 | e2c6 |
| bin (229Mb) | ∨ | - | - | cbow | 500 | 100 | 1c85 |
| bin (229Mb) | ∨ | - | - | skip | 500 | 100 | 54fc |
| bin (494Mb) | ∨ | - | - | skip | 700 | 50 | e235 |
| bin (577Mb) | ∨ | ∨ | - | skip | 700 | 50 | 0695 |
| bin (520Mb) | ∨ | ∨ | - | skip | 1000 | 100 | 8d09 |
| bin (2Gb) | ∨ | - | ∨ | cbow | 500 | 10 | 14da |
| bin (289Mb) | ∨ | - | ∨ | cbow | 500 | 100 | f500 |
frWiki2Vec
FrWiki dump (raw file), 600 millions words.
| lem | pos | phrase | train | dim | cutoff | md5 | |
| bin (253Mb) | - | - | - | cbow | 1000 | 100 | 087c |
| bin (195Mb) | - | - | - | cbow | 1000 | 200 | 0a19 |
| bin (253Mb) | - | - | - | skip | 1000 | 100 | 7d5c |
| bin (195Mb) | - | - | - | skip | 1000 | 200 | 48a0 |
| bin (128Mb) | ∨ | - | - | cbow | 500 | 10 | 052f |
| bin (106Mb) | ∨ | - | - | cbow | 700 | 100 | 8ff0 |
| bin (151Mb) | ∨ | - | - | skip | 1000 | 100 | 5ac9 |
| bin (121Mb) | ∨ | - | - | skip | 1000 | 200 | bc16 |
How to cite those models?
Given the attribution is provided and according to the licence CC-BY 3.0, you are free to copy, distribute, remix and tweak those models for any purpose. The attribution must be made by quoting my name with a link to this page, or by using the bibtex entry below. Those models were trained during my PhD Thesis, and are in no way linked to my current or any future activities. Note also that those models are shared without any guarantees or support.
@misc{fauconnier_2015,
author = {Fauconnier, Jean-Philippe},
title = {French Word Embeddings},
url = {http://fauconnier.github.io},
year = {2015}}
Below, public projects and papers using those models:
- Di Tella et al., (2023), Keep your Enemies Closer: Strategic Platform Adjustments during U.S. and French Elections. in National Bureau of Economic Research (NBER), NBER Working Paper Series. PDF
- Rennard, V., Shang, G., Grari, D., Hunter, J. and Vazirgiannis, M. (2023), FREDSum: A Dialogue Summarization Corpus for French Political Debates. in EMNLP 2023. PDF
- Ait-Saada, M. and Nadif, M. (2023), Unsupervised Anomaly Detection in Multi-Topic Short-Text Corpora. in 17th Conference of the European Chapter of the Association for Computational Linguistic (EACL), Croatia. PDF
- Ivan, I., and Chometton, N. (2022). Alignement des embeddings des définitions et du contexte pour un assistant de lecture sensible au contexte. In Journées Jointes des Groupements de Recherche Linguistique Informatique, Formelle et de Terrain (LIFT) et Traitement Automatique des Langues (TAL). PDF
- Descampe, A., Massart, C., Poelman, S., Standaert, F. X., and Standaert, O. (2022). Automated news recommendation in front of adversarial examples and the technical limits of transparency in algorithmic accountability.. In AI and SOCIETY. Université Catholique de Louvain. PDF
- Eshkol-Taravella, I., Barbedette, A., Liu, X., Soumah, V.-G. (2022) Classification automatique de questions spontanées vs. préparées dans des transcriptions de l’oral. In TALN 2022. PDF
- bpisano (2022). Dall-E Guesser. — Application
- Guillem, F. (2022). Analyse des Programmes de la Présidentielle 2022 avec Word2vec. Le Blog de François Guillem. Blog
- Benamar, A, Grouin, C., Bothua, M. and Vilnat, A. (2022). Etude des stéréotypes genrés dans le théâtre français du XVIe au XIXe siècle à travers des plongements lexicaux. In TALN 2022. PDF
- Enigmatix (2022). Cémantix. Trouvez le mot secret — Application
- Tardy, P. (2021). Approches neuronales pour le résumé abstractif de transcriptions de parole. PhD Thesis Le Mans Université. PDF
- Schoffeniels, A. (2021). NLP Methods for Insurance Document Comparison. Master Thesis University of Liège. PDF
- Mallart, C., Le Nouy, M., Gravier, G., and Sébillot, P. (2021). Active Learning for Interactive Relation Extraction in a French Newspaper's Articles. Recent Advances in Natural Language Processing. PDF
- Barbedette, A., and Eshkol-Taravella, I. (2021). Quand les questions en disent plus que les réponses: classification automatique des intentions dans les questions. Discours (28). OpenEdition
- Wang, X and Liu, X. (2021). Text Classification: du TF-IDF aux word embeddings en passant par features expertes. NLP for French. Blog
- Abdine, H., Xypolopoulos, C., Kamal Eddine, M. and Vazirgiannis, M. (2021). Evaluation of Word Embeddings from Large-Scale French Web Content. arXiv:2105.01990v2. arXiv
- Louis, A., Spanakis, G., and Van Dijck, G. (2021). A Statutory Article Retrieval Dataset in French. arXiv preprint arXiv:2108.11792. arXiv
- Gerardin, M. and Ranvier, M. (2021). Enrichment of the Banque de France’s monthly business survey: lessons from textual analysis of business leaders’ comments. Working Paper — Banque de France. PDF
- Crouzet, O. (2021). Outils computationnels pour l'étude des mécanismes d'adaptation à la variation en perception de la parole. La lettre de I’InSHS — CNRS. PDF
- Dénigot, Q. and Burnett, H. (2021). Using Word Embeddings to Uncover Discourses. In Proceedings of Computation in Linguistics. PDF
- Lambrey, L. (2021). Génération automatique de mots-valises : approche distributionnelle de la classification sémantique de construits. In Journée d'Étude Sciences du Langage, Nancy. PDF
- Billami, M. B., Nicolaieff, L., Gosset, C. and Bortolaso, C. (2021). Participation de Berger-Levrault (BL. Research) à DEFT 2021: de l’apprentissage des seuils de validation à la classification multi-labels de documents. In TALN 2021. PDF
- Hemamou, L. (2021). Analyse automatique des comportements multimodaux lors d’entretiens vidéo différés pour le recrutement. PhD Thesis Université Paris-Saclay. PDF
- Le, N. L. (2020). French Language DRS Parsing. PhD Thesis Mines-Telecom Atlantique. PDF
- Tardy, P., Janiszek, D., Estève, Y., and Nguyen, V. (2020). Align then Summarize: Automatic Alignment Methods for Summarization Corpus Creation. In Proceedings of LREC 2020. PDF
- Blandin, A., Lecorvé, G., Battistelli, D., and Étienne, A. (2020). Age Recommendation for Texts. In Proceedings of LREC 2020. PDF
- Kang, H. J. and Eshkol-Taravella, I. (2020). Les avis sur les restaurants à l’épreuve de l’apprentissage automatique. In TALN 2020. PDF
- Leprieur, L., Crouzet, O., and Gaudrain, E. (2020). Une base de données de phrases en français pour l'étude du rôle conjoint des incertitudes sémantique et acoustique dans la perception de la parole. In TALN 2020. PDF
- Benamar, A. (2020). Segmentation de texte non-supervisée pour la détection de thématiques à l'aide de plongements lexicaux. In TALN 2020. PDF
- Bourdois, L. (2020). L'augmentation de données en NLP. from Chaudhary, A., A Visual Survey of Data Augmentation in NLP. Blog
- Pelloin, V., and Prouteau, T. (2020). Apprentissage de plongements de mots sur des corpus en langue de spécialité: une étude d’impact. In TALN 2020. PDF
- Coulombe, C. (2020). Techniques d’amplification des données textuelles pour l’apprentissage profond. PhD Thesis TÉLUQ. PDF
- Billami, M. (2020). DEESSE: A Generic Search Engine based on Artificial Intelligence. Recherche Berger-Levrault. Blog
- Gilly, A. (2019). The Semantic Architecture of Social Unrest. Blog
- Hemamou, L., Felhi, G., Vandenbussche, V., Martin, J. C., and Clavel, C. (2019). Hirenet: A hierarchical attention model for the automatic analysis of asynchronous video job interviews. In Proceedings of the AAAI Conference on Artificial Intelligence. PDF
- Le Ngoc, L., and Haralambous, Y. (2019). CCG Supertagging Using Morphological and Dependency Syntax Information. In Computational Linguistics and Intelligent Text Processing. PDF
- Chow, J. (2019). Lost in translation: fidelity-focused machine translation evaluation. Master Thesis, Imperial College London. PDF
- Vincent, R. (2019). Multilingual Poetry Generation. Master Thesis Norwegian University of Science and Technology. PDF
- Poelman, S. (2019). Faking news recommendation: an exploration of content representation.. Master Thesis UCL. PDF
- Bladier, T., Waszczuk, J., Kallmeyer, L., and Janke, J. H. (2019). From partial neural graph-based LTAG parsing towards full parsing. Computational Linguistics in the Netherlands Journal. PDF
- Dufter, P., and Schütze, H. (2019). Analytical Methods for Interpretable Ultradense Word Embeddings.. In Proceedings of EMNLP 2019. PDF
- Bardet, A., Loubère, L., Dugué, N., Hu, S. and Delpech, Y. (2019). Proposer des analyses sémantiques ou discursives des contributions du GDN. In Hackatal 2019
- Lettria (2019) — Word embedding. Blog
- De Caigny, K. Coussement, K.W. De Bock, S. Lessmann (2019). Incorporating Textual Information in Customer Churn Prediction Models Based on a Convolutional Neural Network. In International Journal of Forecasting
- Hemamou, L., Felhi, G., Vandenbussche, V., Martin, J.-C. and Clavel, C. (2019). HireNet: a Hierarchical Attention Model for the Automatic Analysis of Asynchronous Video Job Interviews. In AAAI 2019. PDF
- Hmida, F., Billami, M. B., François, T. and Gala, N. (2018). Assisted Lexical Simplification for French Native Children with Reading Difficulties. In Proceedings of the Workshop Automatic Text Adaptation, 11th International Conference on Natural Language Generation (INLG 2018), Tilburg. PDF
- Moot, R. (2017). Combining logical and distributional methods in type-logical grammars. Journal of Language Modelling. HAL
- Dusserre, E., and Padró, M. (2017). Bigger does not mean better! We prefer specificity. In IWCS 2017. Montpellier. PDF
- Linz, N., Tröger, J., Alexandersson, J., and König, A. (2017). Using Neural Word Embeddings in the Analysis of the Clinical Semantic Verbal Fluency Task. In IWCS 2017. Montpellier
- Lefebvre-Brossard, A., Spaeth, A., and Desmarais, M. C. (2017). Encoding User as More Than the Sum of Their Parts: Recurrent Neural Networks and Word Embedding for People-to-people Recommendation. In Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization ACM
- Wang, R. (2017). Second Attempt at Building a Language Translator. Blog
- Sehikh, I., Fohr, D., & Illina, I. (2017). Topic Segmentation in ASR Transcripts using Bidirectional RNNS for Change Detection. In 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). PDF
- Ebert, S. (2017). Artificial Neural Network Methods Applied to Sentiment Analysis. PhD Thesis Ludwig-Maximilians-Universität München. PDF
- Practical Deep Learning For Coders (2017) — Lesson 13 — Fast.ai project
- Povolny, F., Matejka, P., Hradis, M., Popková, A., Otrusina, L., Smrz, P. (2016). Multimodal Emotion Recognition for AVEC 2016 Challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge
- EU Project MixedEmotions (2016) — Social Semantic Emotion Analysis for Innovative Multilingual Big Data Analytics Markets
- Rothe, S., Ebert, S. and Schütze, H. (2016). Ultradense Word Embeddings by Orthogonal Transformation. NAACL 2016. San Diego
- Fauconnier, J. P., Kamel, M. (2015). Discovering Hypernymy Relations using Text Layout. *SEM 2015. Denver. PDF
Annotated copora
Annotated corpora built during my PhD Thesis:
- corpus-LARA: The corpus LARA is a French corpus of Wikipedia pages annotated with enumerative structures.
- corpus-LING_GEOP: LING_GEOP is a corpus with visual and logical clues. The PDF documents come from ANNODIS-ME.
Experience
Laboratory life
- Member of the IRIT doctoral committee
- Member of the JéTou 2015 organization committee
Review
- Subreviewer for ISWC 2016 (Springer)
- Subreviewer for ISWC 2014 (Springer)
- Subreviewer for K-CAP 2013 (ACM)
Jobs & internships
- Axe TAL, CLEE-ERSS, Université Toulouse II, 2012. Evaluation of the French Talismane parser.
- Division ICT, Federal Agency for Medicines and Health Products, Belgium, 2011. Treatment of EudraCT data.
- Software & Technologies, CETIC, Belgium, 2010. Development of the semantic search engine MusOnto.
- Division PRE, Federal Agency for Medicines and Health Products, Belgium, 2009. Database integrity verification.